의미에 대해 생각해보면, multiple regression 모델과 다를 게 없다. Xt 를 이전 p시점까지의 값들로 설명하고자 하는 것이고 ϕp 는 회귀계수, ϵt 는 white noise이다.
위 식에서 우변에 white noise만 남기고 좌변으로 모으면,
(Xt−μ)−ϕ1(Xt−1−μ)−ϕ2(Xt−2−μ)−⋯−ϕp(Xt−p−μ)=ϵt
이 때 Lag operator를 LXt=Xt−1와 같이 L 을 곱하는 식으로 적용이 가능하다고 하면, 흡사 미분방정식의 D=dxd ϕ(L)(Xt−μ)=ϵtwhereϕ(L)=(1−ϕ1L−ϕ2L2−⋯−ϕpLp)
이 때 ϕ(L) 는 AR Operator라고 한다. (1−ϕ1−ϕ2−⋯−ϕp)μ=δ 를 이용하여 Xt=δ+ϕ(L)Xt+ϵt 와 같이 쓰기도 한다.
Moving Average Process, MA Model
AR 모델은 특정 시점의 데이터 Xt 를 과거의 값Xt−1,Xt−2,... 로 설명하는 모델이고, MA 모델은 특정 시점의 데이터 Xt 를 과거의 오차ϵt−1,ϵt−2,... 로 설명하는 모델이다. MA(q) 모델은 다음과 같이 나타낸다.
Xt=μ+ϵt+θ1ϵt−1+⋯+θqϵt−q
이번에도 Operator를 정의해서 θ(L)=(1−θ1L−θ1L2−⋯−θpLq) 라 하면
Xt=μ+θ(L)ϵt
이다.
MA Process는 언제나 Stationary process이다.
ARMA Model
AR모델과 MA모델을 합친 형태.
ϕ(L)(Xt−μ)=θ(L)ϵt
ACF, PACF of AR, MA, ARMA model
AR(p)
ACF: 지수적 감소 or 진동
PACF: p 이후로는 0
MA(q)
ACF: q 이후로는 0
PACF: 지수적 감소 or 진동
ARMA(p,q)
ACF: 지수적 감소 or 진동
PACF: 지수적 감소 or 진동
따라서 Time-series 데이터의 ACF, PACF를 구한 후 어떤 모델을 사용할지 역으로 결정할 수 있다.
Dickey-Fuller test
2024.02.12
Stationarity에 대한 테스트로, trend가 있는지를 테스트하는 것. t-Test를 기반으로 한다.
AR(1) 모델 Xt=ϕXt−1+ϵt 을 예로 들고,
가설을 세운다. H0:ϕ=1 (unit root, non-stationary) H1:∣ϕ∣<1 (stationary)
OLS로 AR(1) 모델을 fit시킨 후, 다음과 같이 t-statistic을 계산하고 테스트를 진행한다. tϕ=1=s.e.(ϕ^)ϕ^−1 보통 회귀에 대해 배울 때 β 라고 쓰던 변수가 ϕ 로 바뀐 것이라고 생각하면 되겠다.
코드
(추후 추가...)
Difference(차분)
2024.02.12
trend를 제거하기 위해 사용하는 방법으로, 데이터 자체가 아닌 변화폭을 기준으로 보는 것
1차 차분: Zt=Xt−Xt−1
2차 차분: Zt=(Xt−Xt−1)−(Xt−1−Xt−2)=Xt−2Xtt−1+Xt−2
ARIMA Model
AutoRegressive Integrated Moving Average ARIMA(p,d,q) 는 ARMA(p,q) 에 d 차 차분 이 추가된 것.

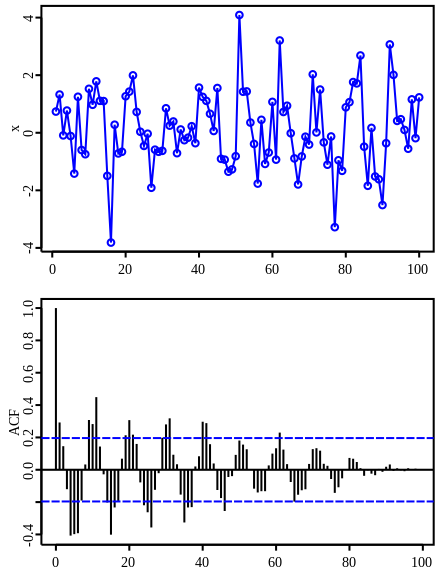 (일단 [위키](https://en.wikipedia.org/wiki/Correlogram) 에서 퍼온 사진)
(일단 [위키](https://en.wikipedia.org/wiki/Correlogram) 에서 퍼온 사진)