고등학교를 다니며 접한 수학 개념들 중 가장 기억에 남는 것은 단연 편미분이고, 학부에서 가장 기억에 남는 것은 역시 Probability Space 이다. 이 블로그의 메인화면과 og이미지, 투각 반지 등에도 새겨놓은 만큼 학부에서 수학에 대한 나의 흥미가 가리킨 방향을 상징하는 개념이다.
전과를 통해 전공을 바꾼 직후에 도합 25학점을 들었던 광란의 2학년 1학기와 여름학기를 거치며 생새우초밥집 사이트와 Stochastic calculus for finance II 라는 책을 알게 되고, 2023년 7~8월간 백남학술정보관 지박령이 되어 이해가 되는 데까지 닥치는 대로 보기 시작한 게 시작이었다.
2학년 2학기에 가끔씩 보고 싶을 때 여러 블로그 글들을 찾아보던 것들을 종합해서, 2학년을 마친 후 방학에 혼자 이것저것 찾아보면서 알게 된 범위까지 정리해놓은 글이 측도론으로 정의하는 확률이었다.
그러고 한동안은 이 내용을 공부하진 못하다가 4학년이 된 후 위상수학을 들을 쯤 딴짓이 땡기는 시험 기간에 지능이 천지개벽한 ChatGPT가 말아주는 확률변수의 정의 적용 예시를 보고 그제서야 아하 moment가 온 적도 있었다.
그리고 대학원 합격 후 또 잊고 살다가, 대학원 첫 학기의 확률 및 통계 첫 수업에서 Probability Space가 바로 나오는 것을 보고 내가 잘 찾아왔구나 싶었다. 그래서 1주차에 해당하는 범위를 공부하면서 더 세세하게 이해하게 된, Probability Space부터 Distribution까지의 내용을 다시 정리해보았다.
Probability Space
Sample Space (Ω)
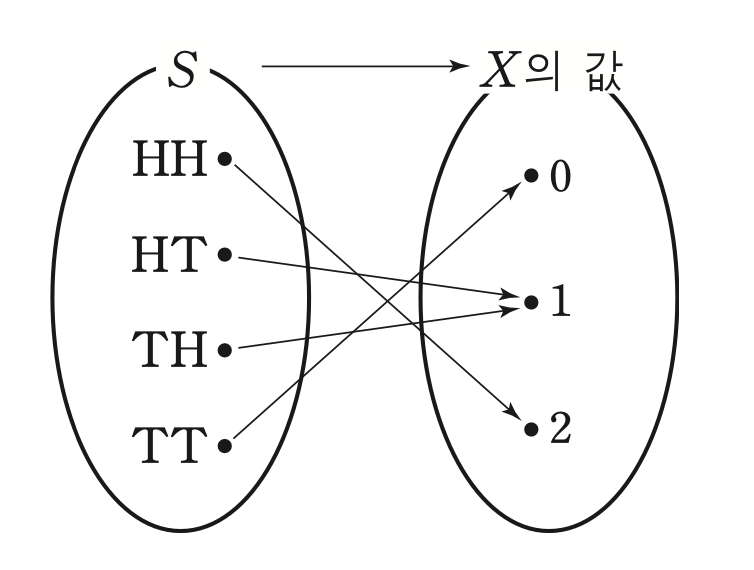
Random experiment의 결과인 outcomeω 를 모두 모아놓은 집합을 Sample spaceΩ 라고 한다.
e.g. 두 개의 동전을 동시에 던지는 random experiment에 대해서는 Ω={HH,HT,TH,TT} 이다.
또한 각 원소를 ω 로 표현하면 ω1=HH,ω2=HT,ω3=TH,ω4=TT 이다.
Event (A)
outcome에 대한 관측은 맥락을 붙여 이루어질 수도 있다. 예를 들어 **'앞면이 한 개만 나오는 사건'**은 {HT,TH} 이다.
이후 정말 다양한 event가 정의된다. 예를 들어
'n 명의 표본을 추출해서 계산한 sample mean과 population mean의 차이가 0.1 이상인 event' 같은 것도 있고 (mode of convergence 중...)
Sample space가 [H,T]N 일 때 'n번째 동전 던지기가 Head인 event' 같은 것도 정의할 수 있다. (limsup of event 중...)
이러한 Ω 의 subset A 를 event 라고 한다. 아무래도 outcome 하나하나를 넘어 그것들의 조합들도 관측/측정을 해야 할테니, event라는 개념을 추가적으로 도입하고 확률을 outcome이 아니라 event에 부여 하는 것은 아주 그럴듯해 보인다.
그리고 Event A 가 발생(occur)한다는 것의 의미는, event Aoccurs if realized outcome ω∈A 이다.
예를 들어 실현된 outcome ω=HT 라면, '앞면이 한 개만 나오는 사건'은 발생(occur)했다고 말할 수 있다.
'앞면이 나오는 사건', '뒷면이 나오는 사건' 같은 것도 발생했다고 말할 수 있을 것이다.
한 가지 문제는, event란 sample space의 subset인데 그럼 sample space의 모든 subset에 확률을 assign할 수 있는가 하는 것이다.
이에 대한 답은... Ω 가 finite/countable이라면 가능하지만 uncountable일 경우에는 불가능하다. (Vitali set 등의 반례)
그렇다면 Ω=[0,1] 과 같은 경우에 대해서도 모든 event에 대해 확률을 부여할 수는 없다는 것인데, 그렇다고 Ω=[0,1] 를 포기할 수는 없으니 무언가 새로운 개념이 필요할 것이다.
σ-algebra
Definition
다음을 만족하는 collection F of subsets of Ω 를 sigma algebra라고 한다.
Ω∈F
A∈F⇒A∁∈F⋯(closed under complement)
A1,A2,...∈F⇒⋃i=1∞Ai∈F⋯(closed under countable unions)
σ-algebra는 결국 확률이 부여될 수 있는 것들이란 무엇인가 에 대한 정보가 잘 정의되어 있는 무언가 정확히는, collection of subsets라고 할 수 있다.
collection of subsets 이니, σ-algebra의 각 원소는 event임을 알 수 있다.
의미
위 3가지 조건을 말로 풀어내면
가능한 모든 사건들 중 하나라도(=Ω) 발생하는 경우에 대해 다룰 수 있어야 하고
어떤 사건 A 에 대해 다룰 수 있다면 그 사건이 일어나지 않는 경우(=A∁) 에 대해서도 다룰 수 있어야 하고,
A1,A2,... 가 있다면, 그중 하나라도 발생하는 경우(=union)에 대해 다룰 수 있어야 한다, 라는 의미에서 저렇게 정의되는 것이라고 보면 되겠다.
예시
-topology처럼 가장 작은 σ-algebra는 F={∅,Ω} 이다.
가장 큰 σ-algebra는 power set F=2Ω 인데,
countable Ω 에 대해서는 Power set도 σ-algebra로 쓰고 probability measure도 정의해서 쓰면 된다.
uncountable Ω 에 대해서는 Power set이 σ-algebra의 정의를 만족할 수 있지만 문제가 터지기 시작한다.
예를 들어 Ω=[0,1], F=2Ω 이면 P([a,b])=b−a 로 probability measure를 정의하는 게 불가능해진다.
2Ω 의 어떤 원소에 대해 P([a,b])=b−a 로 측정이 불가능하냐? 라고 하면 답변으로 Vitali set 같은 게 등장
저렇게 정의해서 uniform distribution을 정의하려면 좀 더 작은 σ-algebra, Borel sigma algebra를 써야 한다. Borel sigma algebra의 중요성이 느껴지기 시작할 수 있는 부분이다.
즉 σ-algebra는 '이게 측정 가능하면 그와 관련된 저것도 측정 가능해야 하고...' 의 의미이지, '이게 만족되어야 확률 부여가 가능하다!' 의 의미는 아니다.
Partition-genearted σ-algebra라는 것도 있다.
정의는 Ω 의 partition {B1,B2,...,Bn} 에 대해 F={∪i∈IBi:I⊆{1,...,n}} 로 복잡하다.
예시가 기억에 남는데, 예를 들어 주사위의 sample space Ω={1,2,3,4,5,6} 를 정의하고 주사위 눈의 홀/짝 여부에만 관심이 있다면 B1={1,3,5},B2={2,4,6} 와 같이 partition을 정의할 수 있다. 그럼 F={∅,B1,B2,Ω} 이다.
Generated σ-algebra
sigma algebra들의 intersection도 sigma algebra라는 점을 이용하면, Ω 의 subset A 에 대해 σ-algabra generated by A 를 다음과 같이 정의할 수 있다.
σ(A)=∩{F:Fis aσ-algebra andA⊆F}
이것의 의미로는 A 을 포함하는 가장 작은 σ-algebra라고도 할 수 있다.
예를 들어 Ω={HH,HT,TH,TT} 일 때 A={HT,TH} 라면 (즉, A 는 앞면이 한 개 나오는 사건)
σ(A)={∅,{HT,TH},{HH,TT},Ω} 이다.
Borel σ-algebra
Borel σ-algebra는 σ-algebra generated by open sets in R 이다.
B(R)=σ({(a,b):a<b})=σ({(−∞,x]:x∈R})⋯(1)⋯(2)
실수 집합 또는 실수 집합의 부분 집합을 sample space로 쓰려면 Borel σ-algebra를 이용할 수 있다.
직관적으로는 실수 집합 R 의 부분 집합이면서 Borel σ-algebra에는 포함되지 않는 것을 떠올리기 어려운데, 이에 대한 예시로도 Vitali set이 있다.
열린 집합의 complement는 닫힌 집합이니 닫힌 집합도 σ-algebra에 포함된다.
(2) 의 정의는 이후 CDF의 정의에 활용된다.
Probability Measure
Definition
다음을 만족하는 함수 P:F→[0,1] 은 (Ω,F) 에 대한 probability measure라고 한다.
Borel measurable function의 정의는 함수 f:R→R 가 ∀B∈B(R)(=Borel set)f−1(B)∈B(R) 이라는 것이다.
심지어 random variable의 limit도 (특정 조건 하에) random variable이다.
Distribution
distribution, 2. cdf, 3. pdf 각각을 순서대로 명확히 구분하며 이해해야 한다.
Probability space (Ω,F,P) 에 정의된 random variable X 에 대해, 먼저 다음과 같은 함수 PX(B) 를 정의한다.
PX(B)=P(X∈B)=P({ω:X(ω)∈B})
이 PX(B) 는 probability measure on (R,B(R)) 이고, 이를 X 의 distribution 이라 한다.
따라서 PX(B) 의 정의역과 공역을 생각해보면, PX:B→R 이다.
Probability Space (Ω,F,P) 에 대한 Random Variable X가 있을 때, X에 대한 distribution μX는 mass를B로 assign하는 measure이다. 이 때 μX(B)=P(X∈B) 이다.
Cumulative Distribution Function
Definition Cumulative Distribution Function of X is: FX(x)=P(X≤x)=PX((−∞,x])
(−∞,x] 는 모두 Borel σ-algebra의 원소이다.
Probability Density Function
Definition
연속적인 X 에 대해, 다음과 같은 함수 f:R→[0,∞) 가 존재할 경우 이를 Probability Distribution Function 이라 한다.
FX(x)=∫−∞xf(t)dt
즉 PDF는 항상 존재성이 보장되는 것은 아니다.
P(a<X≤b)=F(b)−F(a)=∫abf(x)dx
Continuous X 에 대해 P(X=x)=0
확률변수가 확률분포를 '따른다'는 것의 의미
흔히 N(μ,σ2),Unif(a,b),Expo(λ),Pois(λ) 와 같이 표기하는 것들은 probability space와 어떤 관련이 있는 것일지 생각해보면 이게 또 어렵다.
일단 위의 분포들은 모두 distribution에 대한 정보이다. 즉 '이 random variable로부터 특정 값이 튀어나올 확률' 정도를 알려줄 뿐, probability space에 대한 정보를 제공하는 것은 아니다. 즉 다른 두 개의 probability space가 동일한 distribution을 가질 수도 있다.
GPT에서 나온 예시를 보면
(R,B(R),P)whereP(A)=2πσ21e−2σ2(x−μ)2
Random variable X(w)=w
((0,1),B((0,1)),P)whereP(A)=length(A)
Random variable X(w)=Φ−1(w)
이래버리면 위 두 경우는 sample space가 완전히 다르지만 동일한 distribution을 가지게 된다.
하지만 현실적으로 중요한 takeaway는, (보통의 경우에는) 1번과 같이 정의한다면 X∼N(μ,σ2) 과 같이 표기할 수 있다는 점일 것이다.